When Health Advice Comes With No Waiting Room
Chatbots can provide clear advice for routine health questions, but their accuracy declines substantially for more urgent scenarios.

Read Time: 3 minutes
Published:
Most people know what it feels like to consult Dr. Google. You type in a symptom and end up with ten conflicting explanations, a few scary headlines, and a lot of uncertainty. Still, the habit persists because it meets a real need. People want access to answers between appointments. Search engines offer speed, but the results often arrive without clear boundaries between trustworthy guidance and noise. You get health answers fast, but not a clear next step.
Where Google leaves people to sort through the noise, AI chatbots package an answer that sounds ready to trust. Instead of a pile of links, they deliver a single response that sounds organized and is tailored to you. This polish can read like valid medical advice, rather than synthesized information from a variety of sources, which may or may not be comprehensive or accurate. When over 16% of Americans use AI as a go-to source for medical information, the accuracy of its guidance becomes a patient safety issue, and in an emergency, the wrong advice can be life-threatening.
A study led by Ashwin Ramaswamy put ChatGPT Health, a specialized chatbot designed for medical questions, through a structured “stress test” using hypothetical patient scenarios written by clinicians across several areas of medicine. The cases ranged from routine colds and the flu to life-threatening emergencies. Researchers checked whether the chatbot gave the same level of care advice that expert clinicians said each patient needed, from staying home to going to the emergency department right away. The key takeaway was not a single accuracy score, but where the model broke down. It performed differently depending on how urgent the scenario was, as shown in the graphs below.
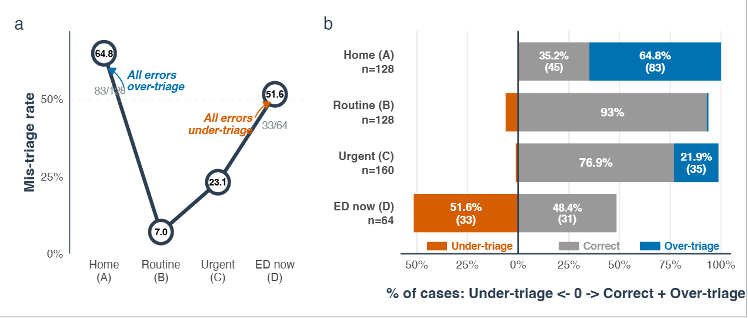
The chatbot performed best on middle-ground cases, with 93% accuracy for routine cases and 76.9% for urgent cases. For non-urgent cases, accuracy dropped to 35.2%, often suggesting unnecessary care. For true emergencies, accuracy dropped to 48.4%. Even worse, the chatbot under-triaged 51.6% of emergency scenarios, recommending slower care when emergency care was needed.
These findings matter because people already use chatbots when deciding whether a symptom can wait or needs immediate care. When access is limited or costly, a confident answer can become a shortcut, even when it is wrong. Under-triage can delay emergency care. Over-triage can send more people to clinics and emergency departments who do not need to be there.
Developers, health systems, regulators, and independent researchers need to treat consumer health chatbots like safety-critical tools, with pre-release testing and crisis safeguards that do not disappear with added details. If the advice can change a patient’s next step, the system should meet safety standards before it reaches the public.



